- 入门篇:图像深度估计相关总结
- 应用篇:Learning to be a Depth Camera
- 尺度篇:Make3D
- 迁移篇:Depth Extraction from Video Using Non-parametric Sampling
- 深度篇:David Eigen
- 无监督篇:Left-Right Consistency & Ego Motion
- 相对深度篇:Depth in the Wild & Size to Depth
- SLAM辅助篇:MegaDepth
- 方法比较篇:Evaluation of CNN-based Methods
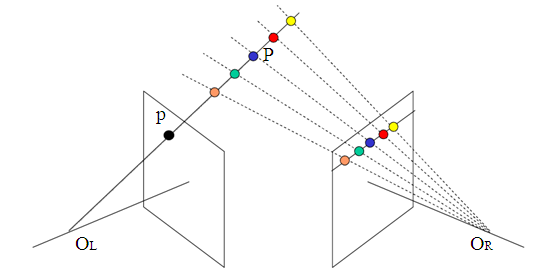
单目图像深度估计 - 2. 应用篇:Learning to be a Depth Camera
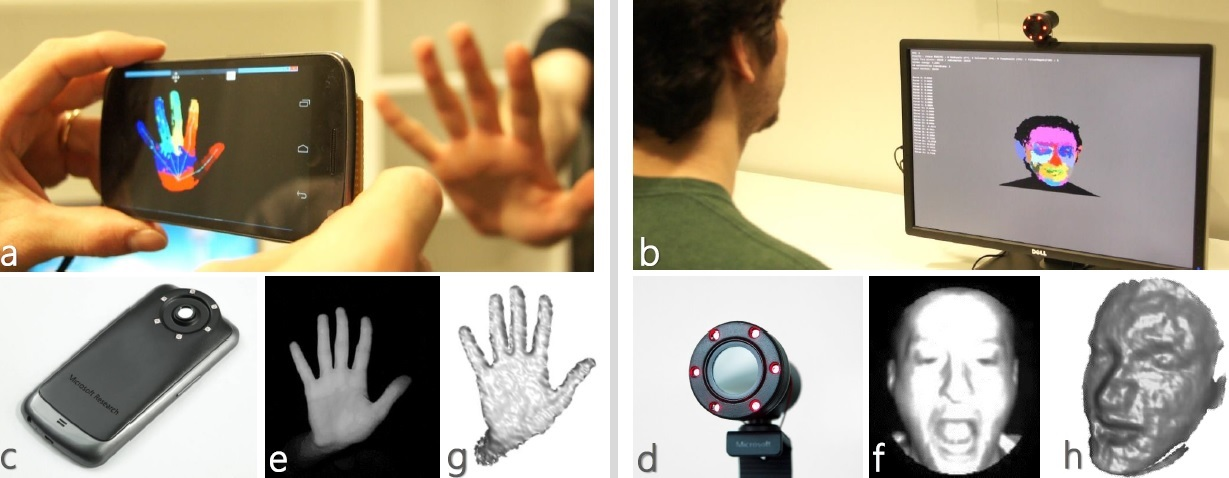
Fig. 1 Learning to be a Depth Camera
第二篇借助Learning to be a Depth Camera for Close-Range Human Capture and Interaction(Website)这篇论文谈一下相关应用。
上篇文章中提到过,有了深度信息后,图片就从二维变成了三维,机器对图像的理解成几何倍数的增长,自然利用这更多的信息可以做到更多的事情。
当机器人可以实时获取空间的三维信息,当人机交互只需要手势和表情,当智能汽车可以实时推断周围物体距离……
Learning to be a Depth Camera这篇论文提供了一种把普通摄像头改造成深度摄像头的方法,结合硬件的改造和机器学习算法推断可实时获取近距离物体的深度信息。在论文配套的视频中展示了多种应用,如人脸3D建模,手势识别等。
Fig. 2 不同应用场景
之所以把这篇叫做应用篇,也是因为在视频中给出的应用场景非常丰富,并且能够直观的深度信息看出在人机交互和3D建模方面的重要性。
硬件改造部分
文中对两种摄像头进行了改造,分别是普通的电脑外接摄像头Microsoft LifeCam(Fig.1 d)和Nexus手机摄像头(Fig.1 c)。
Fig. 3 摄像头改造步骤
如上图,改造的步骤为:
- 去掉相机原有的近红外滤光片(NIR cut filter)
- 增加一个带通滤波片(bandpass filter)
- 增加一圈红色LED光源
其中带通滤波片带宽和新增的LED光源波长均为850nm。
在视频中有详细的改造过程,但此处值得注意的是,目前手机相机镜头可能不是单独的带通滤波片结构,而是一层滤波涂层,因此效果可能会打折。
这种改造的目的是让原本不能感知近红外的镜头对特定波长的近红外光波敏感,改造后的相机输出结果不再为彩色RGB图片。
深度估计算法部分
文章使用机器学习的方法对深度信息进行估计。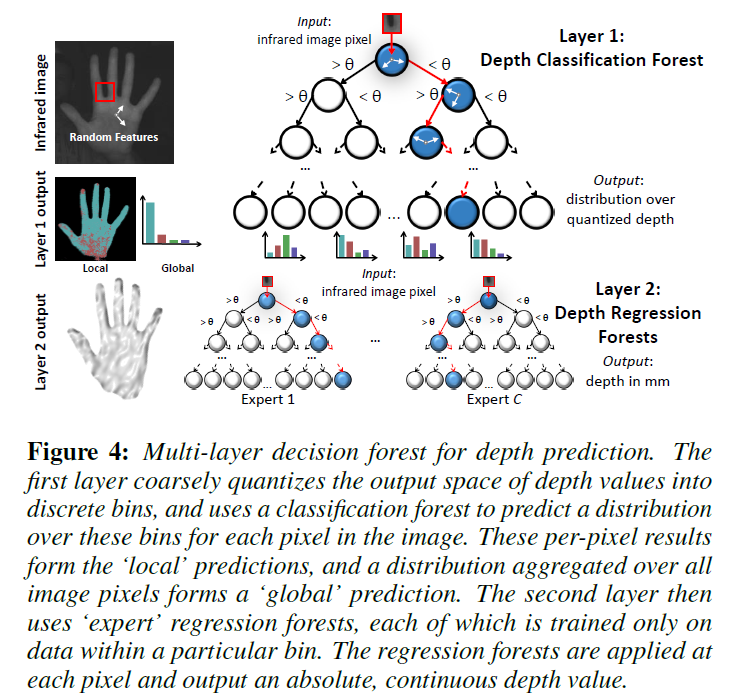
Fig. 4 多层决策森林
Fig.4为文章进行深度估计使用的多层决策森林结构,输入为一个红外图像的像素点,输出为深度距离值。网络为两层结构,第一层为分类森林,第二层为回归森林。为了让预测过程更有效率,文章限制了目标物体的距离范围(20cm到1m)。
如图所示,Layer1为每一个像素分配一块对应的深度范围(每一个叶子节点表示一个深度范围),并且生成整幅图片的预测深度概率分布(计算分别属于c个叶子的概率)。由于叶子节点的输出并不是具体的深度值,且输出中有全局概率分布,因此第一层可理解为全局的粗略深度估计。
此处插播一句,深度特征不同于其他特征的地方有一点就在于深度信息是全局性的,是一种相对的值,人类也会通过相对距离来判断深度,因此大多数深度估计方法都采用一种由粗到细由全局到局部的预测过程,典型的例子就是多尺度深度网络。
Layer2针对layer1的c种分类结果,训练了c个对应的专家树,每一个专家树都由属于此范围的train集进行训练得到。通过激活不同的专家树,并赋予每个(被激活的专家树的)预测结果对应的权重(权重由Layer1给的概率分布决定),获得每个像素点最终的深度预测值。第二层的输出是mm单位的连续深度预测值。
值得注意的是,论文中提到可以使用Kinect获得的真实深度数据对模型进行训练,在应用时使用改造后的摄像头数据,也可以实时产生令人满意的效果。
由于决策树这块我还没吃透,再此不对训练过程做详细说明,大致是通过最大化信息增益得到每个节点的判断阈值的过程。实验对比部分也一并略过。
不足及展望部分
本文提出的方法软硬结合的解决了单目摄像头深度估计问题,优点有成本低廉,实时性强,不需要手动提取特征等,缺点有如下几点:
- 不适用于表面介质不同的物体。文中作对比的SFS方法是基于物体的反射特等物理特性进行深度推测的方法,因此作者强调了此种方法只适用于均一介质的人的皮肤,在视频中也有对塑料模型建模失败的效果展示。
- 需要大量覆盖不同情况的train set。这可能是机器学习和深度学习方法的通病了,过于依赖train集,如用室外数据集KITTI训练得到的深度网络在室内数据集NYU_Depth上的表现往往不尽如人意。
- 只能探测近距离的物体。由于对距离进行了限制(20cm到1m),但也正是因此可以忽略背景的干扰降低了算法复杂度,更适合于人机交互的应用。
作者也提出了可以改进的方向,如利用已有可直接获取红外值的Camera(Omni Vision)获取更精确的结果。
总结和思考
这篇文章值得学习的地方有很多,比如引人入胜的视频,通过视频可以看出作者团队做了多少工作;比如丰富的实验,不仅仅横向与其他算法对比,而且与不同的训练方式对比,同时在论文的结尾还对手部区域分类的应用进行了详细的实验说明;比如软硬结合的方法,在工业应用上这篇文章比其他单独对算法进行改进的论文无疑更有实用价值。
最近一直在思考论文的价值,是发表了论文就算有价值吗?为了提高百分之零点几的正确率让算法变得更加复杂真的是正确的研究方向吗?我个人还是比较喜欢简洁的方法,简洁即优雅,就像Science上的CFSFDP一样,提出全新的思路和方向的论文对我来说更有意思一些。
以上。
[1] Fanello S R, Keskin C, Izadi S, et al. Learning to be a depth camera for close-range human capture and interaction[J]. Acm Transactions on Graphics, 2014, 33(4):1-11.