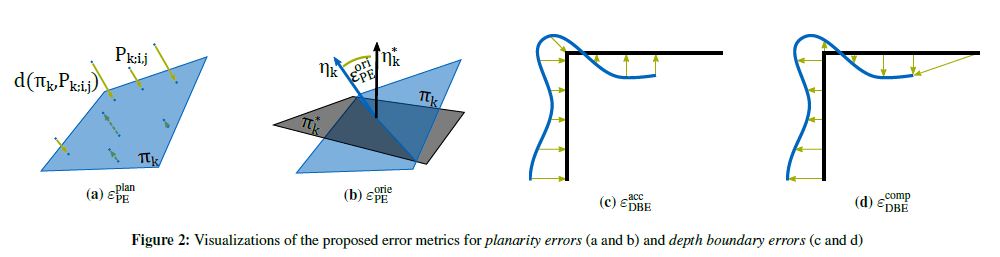
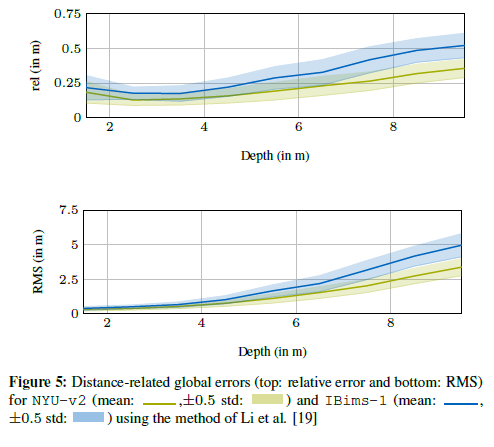
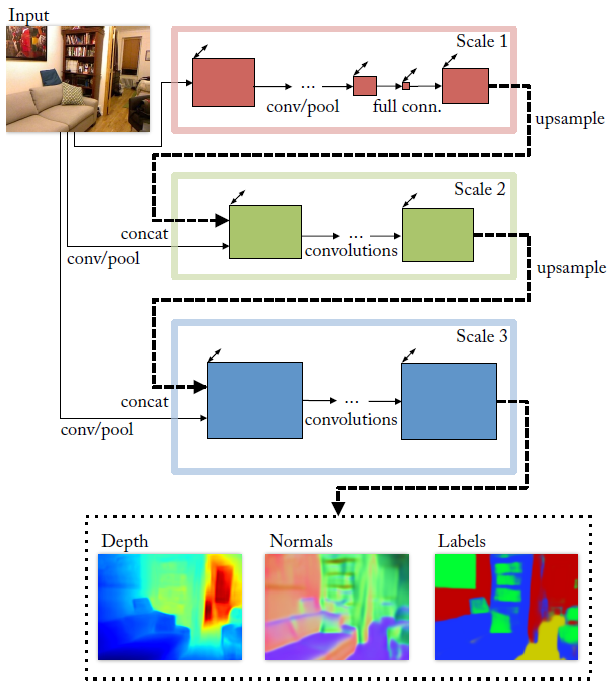
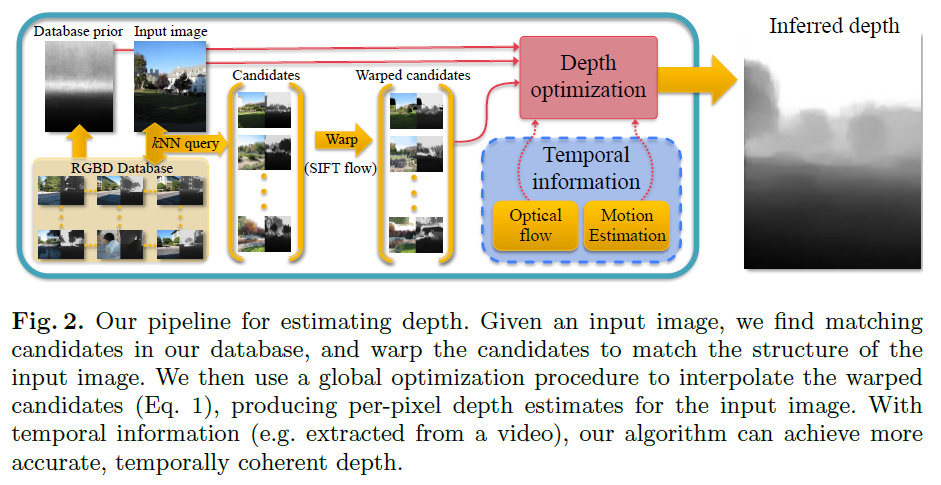
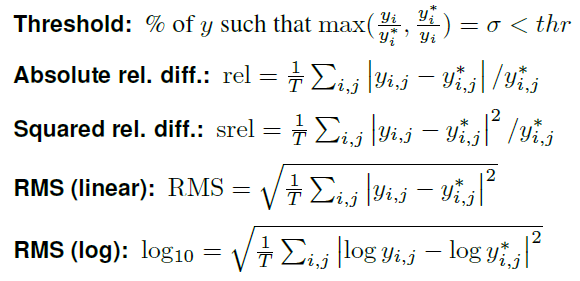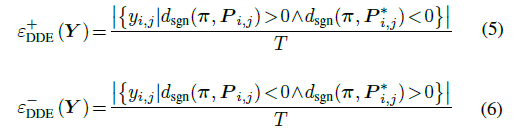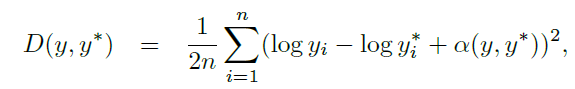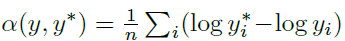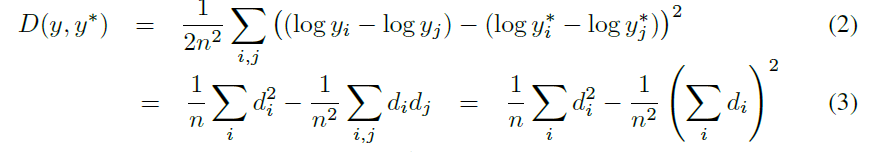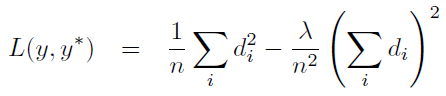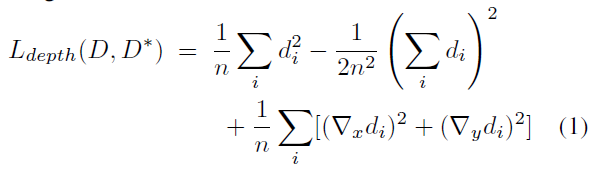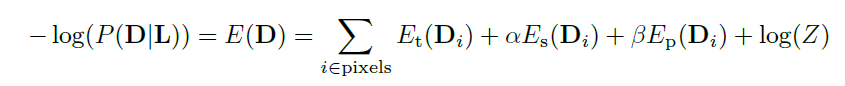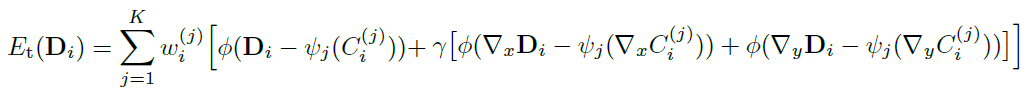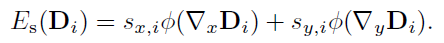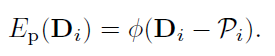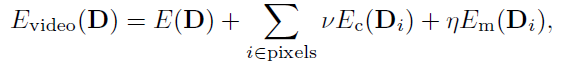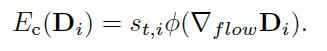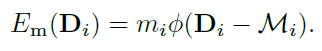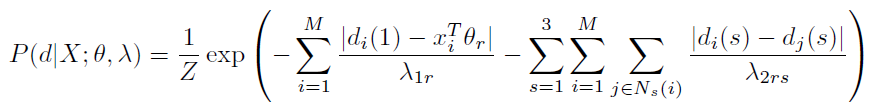OpenCV交叉编译
最近接触了一下板子上的图像处理,完全是从0开始,所以很长一段时间都处于迷茫的自学阶段,不断重复掉坑爬坑掉坑爬坑的过程,心好累然而也没做出什么满意的东西。
这里总结一下里面比较重要的一个环节,OpenCV的交叉编译。
准备工作
从准备工作开始就踩了超多的坑,板子的开发真的好难(流下了宽宽的泪水)。
一开始是在网络上的虚拟机搞,这个虚拟机虽说是linux但是是64位,linux里64位和32位有好多包是不同的,所以在版本匹配上走了好多好多弯路,而且因为公司的网络比较复杂,所以虚拟机和板子是没办法ping通的,最后还是放弃了这个在自己电脑上搭了一个新的。本地虚拟机的优点就是很好ping通,缺点就是我的小电脑亚历山大,根本不敢装图形界面。
装好虚拟机以后就作以下两件事:
安装交叉编译器
由于用的是华为海思的开发板,因此使用海思SDK中提供的交叉编译器,编译器的安装步骤如下:
1)进入Hi3516A_SDK_Vx.x.x.x/osdrv/opensource/toolchain/arm-hisiv300-linux目录,arm-hisiv300-linux.tar.bz2如果没有抽取则抽取到此处,运行chmod +x cross.v300.install,然后运行./cross.v300.install即可。
2) 执行source /etc/profile, 安装交叉编译器的脚本配置的环境变量就可以生效了,或者请重新登陆也可。
3) 安装好的交叉编译器一般在/opt目录下。
安装CMake
1) 网站下载代码https://cmake.org/download/
2) 解压到~/目录 tar -xvf cmake-3.11.0-Linux-x86_64.tar.gz
3) 为cmake创建连接 sudo ln -s ~/cmake-3.11.0-Linux-x86_64/bin/* /usr/bin/
4) 测试 cmake –version
编译
这个过程用六个字来概括就是“尽人事,听天命”,过程中会出现超多的莫名其妙的报错,有的居然通过重启虚拟机就可以解决,百思不得其解啊。
以下为复制别人的内容,因为这个过程漫长又不可控,所以我自己的记录比较少,我在编译过程中遇见的问题会在最后一部分总结以下,这部分就写一下如果不出错流程会是怎样:
1、修改cmake文件
在源码的platforms下已经有对各平台的交叉编译支持,我们只需要做一些简单的修改。
[zzz@localhost platforms]$ pwd
/home/zzz/software/opencv-3.1.0/platforms
[zzz@localhost platforms]$ ll
total 28
drwxr-xr-x. 4 zzz zzz 4096 Dec 18 23:02 android
drwxr-xr-x. 3 zzz zzz 4096 Dec 18 23:02 ios
drwxr-xr-x. 4 zzz zzz 4096 Jan 22 17:24 linux
drwxr-xr-x. 2 zzz zzz 4096 Dec 18 23:02 osx
-rw-r–r–. 1 zzz zzz 323 Dec 18 23:02 readme.txt
drwxr-xr-x. 2 zzz zzz 4096 Dec 18 23:02 scripts
drwxr-xr-x. 2 zzz zzz 4096 Dec 18 23:02 winrt
我们的目标是交叉编译到arm上,那么就进入到linux下:
[zzz@localhost linux]$ pwd
/home/zzz/software/opencv-3.1.0/platforms/linux
[zzz@localhost linux]$ ll
total 20
-rw-r–r–. 1 zzz zzz 4196 Jan 22 16:35 arm-gnueabi.toolchain.cmake
…
arm-gnueabi.toolchain.cmake指明了交叉编译的一些路径等设置,我们根据实际情况对其进行适当修改:
set(CMAKE_SYSTEM_NAME Linux)
set(CMAKE_SYSTEM_VERSION 1)
set(CMAKE_SYSTEM_PROCESSOR arm-hisiv300-linux-gnueabi)
set(GCC_COMPILER_VERSION “4.6” CACHE STRING “GCC Compiler version”)
set(FLOAT_ABI_SUFFIX “”)
if (NOT SOFTFP)
set(FLOAT_ABI_SUFFIX “hf”)
endif()
#CROSS COMPILE SETTING
set(TOOLCHAIN_DIR “/opt/hisi-linux/x86-arm/arm-hisiv300-linux/“)
set(CMAKE_C_COMPILER “/opt/hisi-linux/x86-arm/arm-hisiv300-linux/bin/arm-hisiv300-linux-uclibcgnueabi-gcc”)
set(CMAKE_CXX_COMPILER “/opt/hisi-linux/x86-arm/arm-hisiv300-linux/bin/arm-hisiv300-linux-uclibcgnueabi-g++”)
set(CMAKE_FIND_ROOT_PATH /opt/hisi-linux/ /opt/hisi-linux/x86-arm/arm-hisiv300-linux/)
set(ARM_LINUX_SYSROOT /opt/hisi-linux/x86-arm/arm-hisiv300-linux/ CACHE PATH “ARM cross compile system root”)
MESSAGE(STATUS “This is cross compile dir —>”$(CMAKE_C_COMPILER))
#find_program(CMAKE_C_COMPILER NAMES arm-linux-gnueabi${FLOAT_ABI_SUFFIX}-gcc-${GCC_COMPILER_VERSION})
#find_program(CMAKE_CXX_COMPILER NAMES arm-linux-gnueabi${FLOAT_ABI_SUFFIX}-g++-${GCC_COMPILER_VERSION})
#set(ARM_LINUX_SYSROOT /usr/arm-linux-gnueabi${FLOAT_ABI_SUFFIX} CACHE PATH “ARM cross compilation system root”)
#set(CMAKE_CXX_FLAGS "" CACHE STRING "c++ flags")
#set(CMAKE_C_FLAGS “” CACHE STRING “c flags”)
#set(CMAKE_SHARED_LINKER_FLAGS “” CACHE STRING “shared linker flags”)
#set(CMAKE_MODULE_LINKER_FLAGS “” CACHE STRING “module linker flags”)
#set(CMAKE_EXE_LINKER_FLAGS “-Wl,-z,nocopyreloc” CACHE STRING “executable linker flags”)
set(CMAKE_CXX_FLAGS “${CMAKE_CXX_FLAGS} -mthumb -fdata-sections -Wa,–noexecstack -fsigned-char -Wno-psabi”)
set(CMAKE_C_FLAGS “${CMAKE_C_FLAGS} -mthumb -fdata-sections -Wa,–noexecstack -fsigned-char -Wno-psabi”)
set(CMAKE_SHARED_LINKER_FLAGS “-Wl,–fix-cortex-a8 -Wl,–no-undefined -Wl,–gc-sections -Wl,-z,noexecstack -Wl,-z,relro -Wl,-z,now ${CMAKE_SHARED_LINKER_FLAGS}”)
set(CMAKE_MODULE_LINKER_FLAGS “-Wl,–fix-cortex-a8 -Wl,–no-undefined -Wl,–gc-sections -Wl,-z,noexecstack -Wl,-z,relro -Wl,-z,now ${CMAKE_MODULE_LINKER_FLAGS}”)
set(CMAKE_EXE_LINKER_FLAGS “-Wl,–fix-cortex-a8 -Wl,–no-undefined -Wl,–gc-sections -Wl,-z,noexecstack -Wl,-z,relro -Wl,-z,now ${CMAKE_EXE_LINKER_FLAGS}”)
if(USE_NEON)
message(WARNING “You use obsolete variable USE_NEON to enable NEON instruction set. Use -DENABLE_NEON=ON instead.” )
set(ENABLE_NEON TRUE)
elseif(USE_VFPV3)
message(WARNING “You use obsolete variable USE_VFPV3 to enable VFPV3 instruction set. Use -DENABLE_VFPV3=ON instead.” )
set(ENABLE_VFPV3 TRUE)
endif()
#set(CMAKE_FIND_ROOT_PATH ${CMAKE_FIND_ROOT_PATH} ${ARM_LINUX_SYSROOT})
if(EXISTS ${CUDA_TOOLKIT_ROOT_DIR})
set(CMAKE_FIND_ROOT_PATH ${CMAKE_FIND_ROOT_PATH} ${CUDA_TOOLKIT_ROOT_DIR})
endif()
set( CMAKE_SKIP_RPATH TRUE CACHE BOOL “If set, runtime paths are not added when using shared libraries.” )
set(CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY)
set(CMAKE_FIND_ROOT_PATH_MODE_PROGRAM ONLY)
# macro to find programs on the host OS
macro( find_host_program )
set( CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER )
set( CMAKE_FIND_ROOT_PATH_MODE_LIBRARY NEVER )
set( CMAKE_FIND_ROOT_PATH_MODE_INCLUDE NEVER )
if( CMAKE_HOST_WIN32 )
SET( WIN32 1 )
SET( UNIX )
elseif( CMAKE_HOST_APPLE )
SET( APPLE 1 )
SET( UNIX )
endif()
find_program( ${ARGN} )
SET( WIN32 )
SET( APPLE )
SET( UNIX 1 )
set( CMAKE_FIND_ROOT_PATH_MODE_PROGRAM ONLY )
set( CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY )
set( CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY )
endmacro()
# macro to find packages on the host OS
macro( find_host_package )
set( CMAKE_FIND_ROOT_PATH_MODE_PROGRAM NEVER )
set( CMAKE_FIND_ROOT_PATH_MODE_LIBRARY NEVER )
set( CMAKE_FIND_ROOT_PATH_MODE_INCLUDE NEVER )
if( CMAKE_HOST_WIN32 )
SET( WIN32 1 )
SET( UNIX )
elseif( CMAKE_HOST_APPLE )
SET( APPLE 1 )
SET( UNIX )
endif()
find_package( ${ARGN} )
SET( WIN32 )
SET( APPLE )
SET( UNIX 1 )
set( CMAKE_FIND_ROOT_PATH_MODE_PROGRAM ONLY )
set( CMAKE_FIND_ROOT_PATH_MODE_LIBRARY ONLY )
set( CMAKE_FIND_ROOT_PATH_MODE_INCLUDE ONLY )
endmacro()
2、交叉编译
设置好了以后,开始进行交叉编译:
建立好执行cmake的路径:build_softfp,建立好编译后的安装路径:install_dir
[zzz@localhost linux]$ ll
total 20
-rw-r–r–. 1 zzz zzz 4196 Jan 22 16:35 arm-gnueabi.toolchain.cmake
drwxrwxr-x. 15 zzz zzz 4096 Jan 22 16:38 build_softfp
drwxrwxr-x. 6 zzz zzz 4096 Jan 22 15:51 install_dir
执行:
[zzz@localhost build_softfp]$ pwd
/home/zzz/software/opencv-3.1.0/platforms/linux/build_softfp
[zzz@localhost build_softfp]$ cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=../install_dir/ -D SOFTFP=ON -D ENABLE_NEON=ON -D CMAKE_TOOLCHAIN_FILE=../arm-gnueabi.toolchain.cmake ../../../
等待10几分钟。
问题总结
- make报错提示“No suitable threading library available”: 定位到common.cc文件,头文件首行加上#define HAVE_PTHREAD
- 提示找不到bits/auxv.h: 搜索发现在/usr/include/x86_64-linux-gun/bits/auxv.h,更改对应文件的include
- 查看arm-linux-gcc编译器的版本arm-linux-gcc -v时报错bin/.arm-none-linux-gnueabi-gcc: not found:
a. 解决方法一:sudo apt-get install lsb-core但出现安装失败
b. 解决方法二:原因可能是64位ubuntu系统缺少某些32位包,只要装一下ia32-libs就ok了.但是,貌似从ubuntu 13.10之后就没有ia32-libs了,因此sudo apt-get install lib32stdc++6 lib32z1 lib32ncurses5 lib32bz2-1.0,但还是出现安装失败。
但是!此时可以输出版本信息了!于是pass
- ubuntu16.04安装32位交叉编译工具链的兼容包:
apt-get install lib32ncurses5
apt-get install lib32z1
- 配置linux内核时报错curses.h: No such file or directory:
Sudo apt-get install libncurses5-dev libncursesw5-dev
- 错误:error while loading shared libraries: libstdc++.so.6: cannot open shared object file: No such file or direcory。
$sudo apt-get install libstdc++6
$sudo apt-get install lib32stdc++6
- 输入命令语句为:make ARCH=arm CROSS_COMPILE=arm-hisiv500-linux- uImage
报错信息为:
kernel/power/swap.c:1168:10: error: ‘RESTARTSYS’ undeclared (first use in this function)
return -RESTARTSYS;
cp arch/arn/configs/hi3518ev200_full_defconfig .config —> 这句要执行好, 是3518的配置文件。
如果没有拷贝成功, 则在进行menuconfig时, 没有3518ev200的一些选择项。 比如没有拷贝就执行menuconfig, 则在菜单选项,I2C 目录中没有3518 的选项。 如果 执行成功, 就有3518 I2C 的选项。
- 编译linux kernel uImage时提示:“mkimage” command not found – U-Boot images will not be built:
sudo apt-get install u-boot-tools
- 错误提示:ECHO : not found等一系列found问题
首先用whereis echo查看echo所在路径
然后用export查看PATH中包含的路径
发现包含无误,则修改文件第一句#!/bin/sh为#!/bin/bash即可